开发板评测
oracle
集群模式
静息态
https
类型转换
IAR
健身私教预约系统
图像半自动标注
salesforce
select函数
csrf
敖丙
集成测试
Cookie
webdav
传输层
Security
gns3
正则表达式-常用功能
多模态大模型
2024/9/22 16:32:47
5款极其强大的大模型文生图工具!
文生图技术是一种基于深度学习的技术,可以根据自然语言描述生成相应的高品质图像。
下面介绍几个目前市场上比较优秀的工具或网站,并制作一张男性的白袍巫师图来比较。
针对大模型和AIGC技术趋势、AIGC 算法项目落地经验分享、新手如何入门算法岗、该如…

【多模态大模型】的正确打开方式——图片
早期痛点
识别图片中的物体,早期可以使用Yolo 但是缺点也很明显:
训练时间长成本高泛华性能差通用识别领域覆盖有限
优点:
特殊领域识别
大模型出现
大模型出现后,一些大模型对接了图片识别相关的模型,实现了图片…

Transformer动画讲解:Cross Attention
暑期实习基本结束了,校招即将开启。
不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。提前准备才是完全之策。
最近,我们又陆续整理了很多大厂的面试题,…

面完英伟达算法岗,心态崩了。。。
最近这一两周看到不少互联网公司都已经开始秋招提前批了。不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。
最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解…

扩散模型 GLIDE:35 亿参数的情况下优于 120 亿参数的 DALL-E 模型
节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学。
针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。
合集&#x…

面试美团大模型算法岗,问的贼细。。。
最近这一两周看到不少互联网公司都已经开始秋招提前批了。
不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。
最近,我们又陆续整理了很多大厂的面试题,帮助一些球友…

全球首个!清华/上海交大等联合构建面向糖尿病诊疗的视觉-大语言模型,登 Nature 子刊
糖尿病是全球上升最快的主要慢性病,可造成失明、肾功能衰竭、截肢、脑卒中、心肌梗死等,亦与肿瘤感染等密切相关。其中,糖尿病视网膜病变 (diabetic retinopathy, DR) 是糖尿病患者最常见的进行性眼部微血管并发症,能够影响 30-40…

RAG+Agent人工智能平台:RAGflow实现GraphRA知识库问答,打造极致多模态问答与AI编排流体验
1.RAGflow简介 全面优化的 RAG 工作流可以支持从个人应用乃至超大型企业的各类生态系统。大语言模型 LLM 以及向量模型均支持配置。基于多路召回、融合重排序。提供易用的 API,可以轻松集成到各类企业系统。支持丰富的文件类型,包括 Word 文档、PPT、exc…

第五节 LLaVA模型lora推理模型解读(下篇)
文章目录 前言一、lora推理主函数源码解读二、ModelWorker类初始化源码解读三、load_pretrained_model函数解读1、整体源码说明2、语言模型加载3、non_lora_trainables权重修改源码解读4、non_lora_trainables权重加载源码解读5、语言模型lora权重载入与合并6、视觉模型7、visi…

LLM - 理解 多模态大语言模型 (MLLM) 的发展与相关技术 (一)
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/142063880 免责声明:本文来源于个人知识与公开资料,仅用于学术交流,欢迎讨论,不支持转载。 多模态…
面试字节视觉大模型算法岗,太难了。。。
最近这一两周看到不少互联网公司都已经开始秋招提前批面试了。
不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。
最近,我们又陆续整理了很多大厂的面试题,帮助一些…
大语言模型(LLM)如何更好地继续预训练(Continue PreTraining)
预训练(Pretraining)是一个非常消耗资源的工作,尤其在 LLM 时代。随着LLama2的开源,越来越多人都开始尝试在这个强大的英文基座模型上进行中文增强。但,我们如何才能保证模型在既学到「中文知识」的情况下,…
大白话说什么是“MLLM”多模态大语言模型
1. 什么是MLLM多模态大语言模型
1.1 先来思考一个问题
如果上传了一张图片,并向大模型提问。“图片中绿色框框中的人是谁?”
大模型回答:“那是波多野吉衣老师”
请问,大模型是怎么做到的?
我们用常规的思路来想一…

【多模态/CV】图像数据增强数据分析和处理
note
多模态大模型训练前,图片数据处理的常见操作:分辨率调整、网格畸变、水平翻转、分辨率调整、随机crop、换颜色、多张图片拼接、相似图片检测并去重等 文章目录 note一、分辨率调整二、适当裁剪图片三、网格畸变、水平翻转、平移缩放、旋转四、改变…

LLM系列 | 38:解读阿里开源语音多模态模型Qwen2-Audio
引言 模型概述 模型架构 训练方法 性能评估 实战演示 总结
引言
金山挂月窥禅径,沙鸟听经恋法门。 小伙伴们好,我是微信公众号《小窗幽记机器学习》的小编:卖铁观音的小男孩,今天这篇小作文主要是介绍阿里巴巴的语音多模…
开源 LLM 微调训练指南:如何打造属于自己的 LLM 模型
一、介绍
今天我们来聊一聊关于LLM的微调训练,LLM应该算是目前当之无愧的最有影响力的AI技术。尽管它只是一个语言模型,但它具备理解和生成人类语言的能力,非常厉害!它可以革新各个行业,包括自然语言处理、机器翻译、…

大模型应用实践:AIGC探索之旅
随着OpenAI推出ChatGPT,AIGC迎来了前所未有的发展机遇。大模型技术已经不仅仅是技术趋势,而是深刻地塑造着我们交流、工作和思考的方式。
本文介绍了笔者理解的大模型和AIGC的密切联系,从历史沿革到实际应用案例,再到面临的技术挑…

如何通过 Prompt 优化大模型 Text2SQL 的效果
前言
在上篇文章中「大模型LLM在Text2SQL上的应用实践」介绍了基于SQLDatabaseChain的Text2SQL实践,但对于逻辑复杂的查询在稳定性、可靠性、安全性方面可能无法达到预期,比如输出幻觉、数据安全、用户输入错误等问题。
本文将从以下4个方面探讨通过Pr…
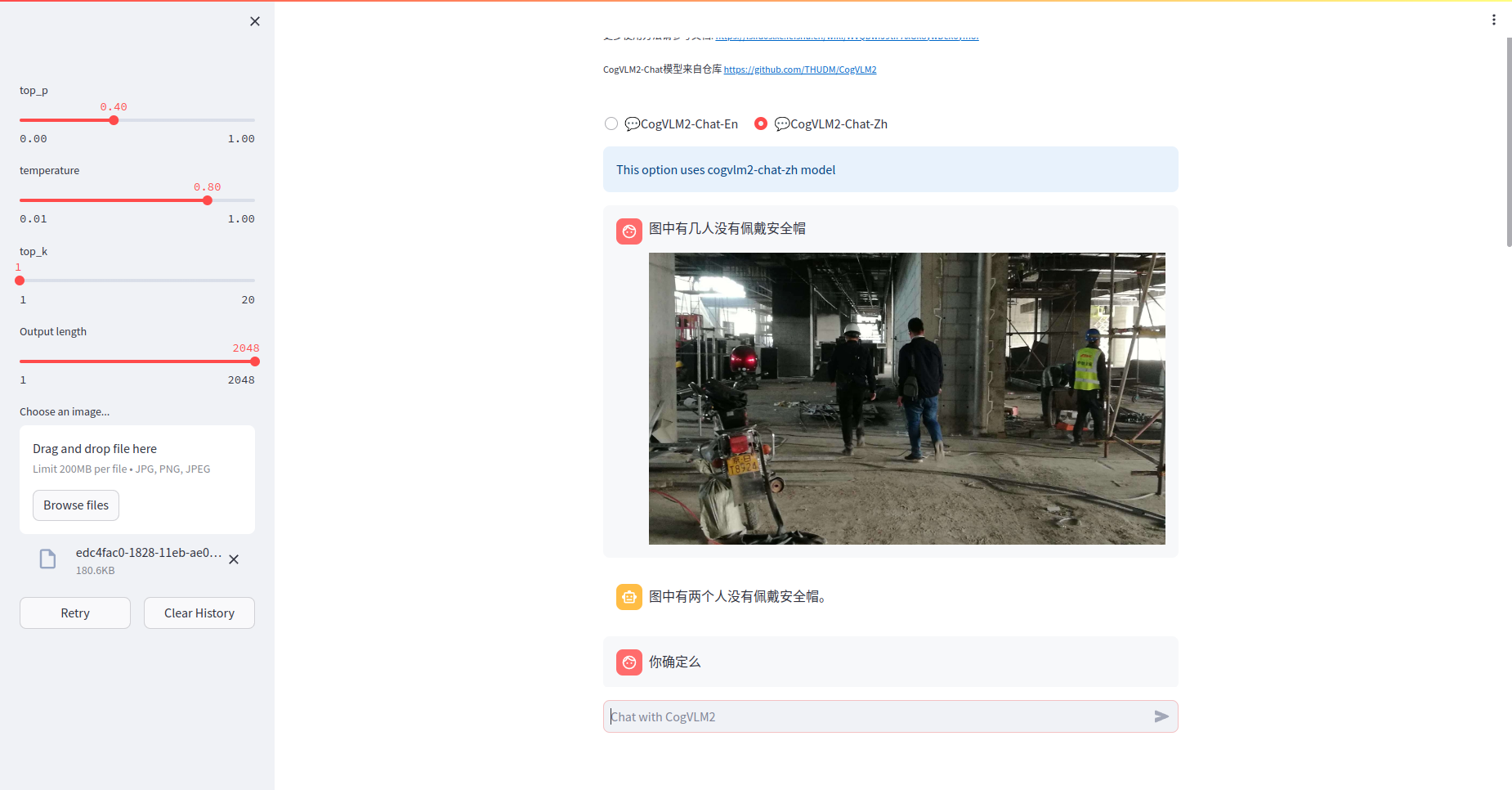
CogVLM2 本地部署体验(Docker容器版)
智普AI推出新一代的 CogVLM2 系列模型,并开源了两款基于 Meta-Llama-3-8B-Instruct开源模型。与上一代的 CogVLM 开源模型相比,CogVLM2 系列开源模型具有以下改进:
在许多关键指标上有了显著提升,例如 TextVQA, DocVQA。支持 8K …
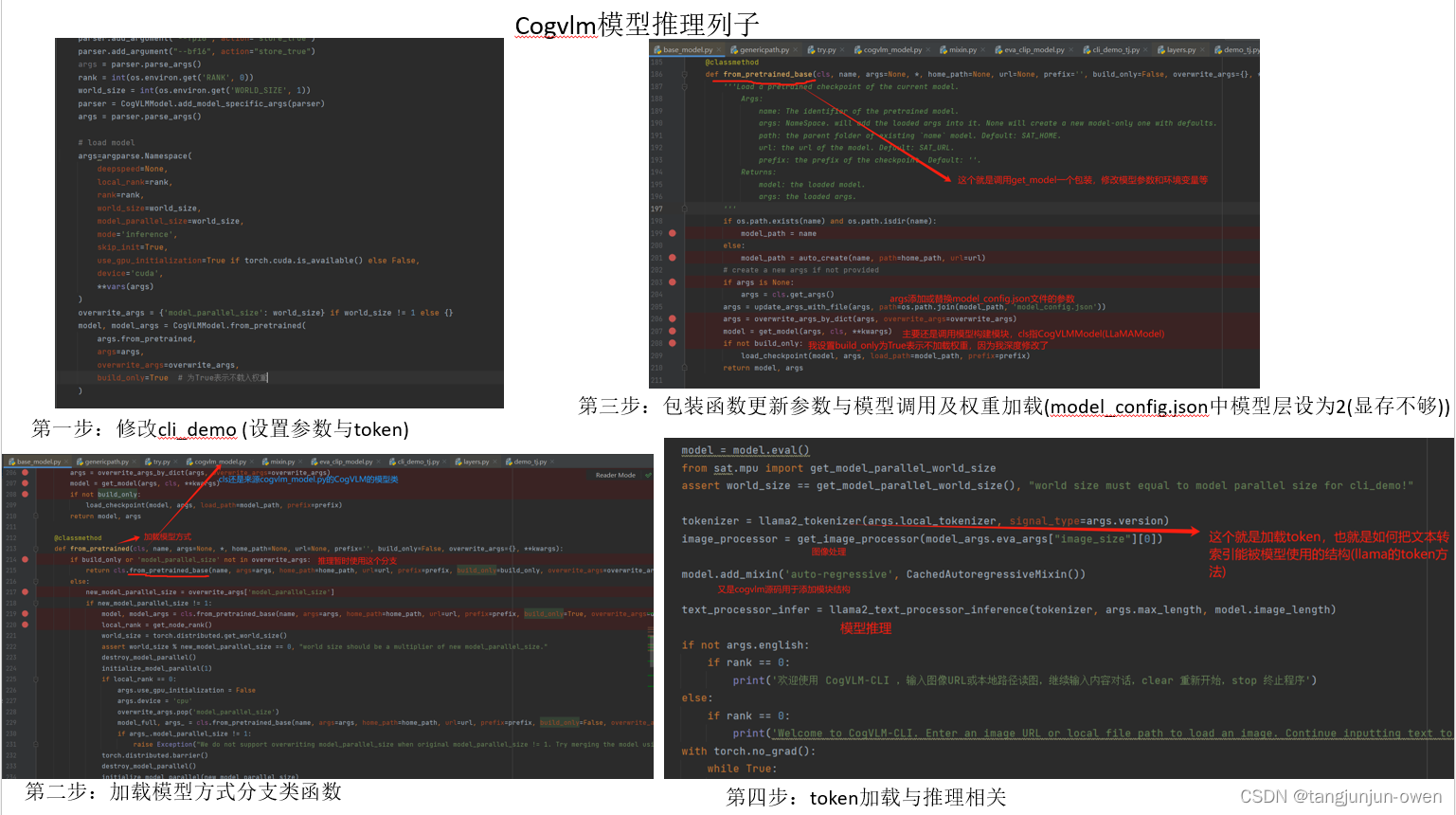
CogVLM大模推理代码详细解读
文章目录 前言一、参数介绍1.cogvlm-grounding-generalist参数介绍 二、模型构建1、创建主函数(get_model)2、调用sat库模型构建函数(base_model.py)3、模型类构建模型(self.add_mixin)4、整体结构5、模型运行结果 三、CogVLM推理源码解读1、推理整体代码2、CogVLMModel.from_p…

LLM - 理解 多模态大语言模型(MLLM) 的 评估(Evaluation) 与相关技术 (六)
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/142364884 免责声明:本文来源于个人知识与公开资料,仅用于学术交流,欢迎讨论,不支持转载。 评估(E…

共计3万字!从零开始创建一个小规模的稳定扩散模型!
节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学。
针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。
合集&#x…

深度剖析现阶段的多模态大模型做不了医疗
导读
在人工智能的这波浪潮中,以ChatGPT为首的大语言模型(LLM)不仅在自然语言处理(NLP)领域掀起了一场技术革命,更是在计算机视觉(CV)乃至多模态领域展现出了令人瞩目的潜力。
这些…

一文详解去噪扩散概率模型(DDPM)
节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学。
针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。
合集&#x…

源码解析:从零解读SAM(Segment Anything Model)大模型!
节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学。
针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。
合集&#x…

本科生大厂算法岗实习经验复盘:从投递到面试的底层思维!
目录 投递渠道boss直聘官网邮箱内推 面试准备leetcode八股深挖项目自我介绍mock面试技巧答不出来怎么办coding反问 复盘技术交流群用通俗易懂方式讲解系列 节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面…

AIGC 技术在淘淘秀场景的探索与实践
本文介绍了AIGC相关领域的爆发式增长,并探讨了淘宝秀秀(AI买家秀)的设计思路和技术方案。文章涵盖了图像生成、仿真形象生成和换背景方案,以及模型流程串联等关键技术。
文章还介绍了淘淘秀的使用流程和遇到的问题及处理方法。最后,文章展望…

轻松构建聊天机器人,大模型 RAG 有了更强大的AI检索器
节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学。
针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。
合集&#x…

2024年大模型面试准备(二):LLM容易被忽略的Tokenizer与Embedding
分词和嵌入一直是LM被忽略的一部分。随着各大框架如HF的不断完善,大家对tokenization和embedding的重视程度越来越低,到现在初学者大概只能停留在调用tokenizer.encode这样的程度了。
知其然不知其所以然是很危险的。比如你要调用ChatGPT的接口…
AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.05.20-2024.05.25
文章目录~ 1.LM4LV: A Frozen Large Language Model for Low-level Vision Tasks2.Disease-informed Adaptation of Vision-Language Models3.VDGD: Mitigating LVLM Hallucinations in Cognitive Prompts by Bridging the Visual Perception Gap4.Composed Image Retrieval fo…

BLIP2——采用Q-Former融合视觉语义与LLM能力的方法
BLIP2——采用Q-Former融合视觉语义与LLM能力的方法 FesianXu 20240202 at Baidu Search Team 前言
大规模语言模型(Large Language Model,LLM)是当前的当红炸子鸡,展现出了强大的逻辑推理,语义理解能力,而视觉作为人…

高维多变量下的Transformer时序预测建模方法
今天给大家介绍一篇CIKM 2024中的时间序列预测工作,这篇文章针对高维多变量时序预测问题,提出了一种基于Transformer的建模方法。 论文标题:Scalable Transformer for High Dimensional Multivariate Time Series Forecasting
下载地址&…

视觉理解与图片问答,学习如何使用 GPT-4o (GPT-4 Omni) 来理解图像
🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 一、引言 OpenAI 最新发布的 GPT-4 Omni 模型,也被称为 GPT-4o,是一个多模态 AI 模型,旨在提供更加自然和全面的人机交互体验。
GPT-4o 与 GPT-4 Turbo 都具备视觉功…

【分割大模型】SAM2(Segment Anything2)新的分割一切大模型(原理+安装+代码)
文章目录 前言1.特点2.结构3.应用场景 一、原理1.1 引言1.2 任务:可提示的视觉分割1.3 模型1.4 数据引擎 与 SA-V数据集 二、安装与使用 项目地址:https://github.com/facebookresearch/segment-anything-2
前言 Segment Anything Model 2(S…

2024自动驾驶(多模态)大模型综述:从DriveGPT4、DriveMLM到DriveLM、DriveVLM
前言
由于今年以来,一直在不断深挖具身智能机器人相关,而自动驾驶其实和机器人有着无比密切的联系,甚至可以认为,汽车就是一个带着4个轮子的机器人
加之个人认为,目前大模型落地潜力最大的两个方向,一个是…

北大和鹏城实验室联合推出的图像视频统一多模态大模型Chat-UniVi(CVPR 2024)
Chat-UniVi: Unified Visual Representation Empowers Large Language Models with Image and Video Understanding
论文信息
paper:CVPR 2024 code:https://github.com/PKU-YuanGroup/Chat-UniVi 训练130亿大模型仅3天,北大提出Chat-UniVi…
多模态基础大模型-预训练解决方案 2024
当前,新一代人工智能已成为世界各国的竞争焦点,抢占未来技术战略制高点意义重大。由于持续开放的动态环境、各行业领域不断攀升的系统复杂度以及快速扩大的数据规模总量,智能技术应用需求不断增长,智能形态和认知水平持续深入发展…

OpenAI Embedding效果表现不佳:那如何评估选择Embedding?
OpenAI Embedding效果表现不佳
对文本进行Embedding是大模型应用中必不可少的一步, 虽然大模型OpenAI是最好的, 但OpenAI的Embedding却不是。本文Embedding评估的具体流程, 代码, 以及结论。
如果仅关心代码 & 结论…

AIGC元年大模型发展现状手册
零、AIGC大模型概览
AIGC大模型在人工智能领域取得了重大突破,涵盖了LLM大模型、多模态大模型、图像生成大模型以及视频生成大模型等四种类型。这些模型不仅拓宽了人工智能的应用范围,也提升了其处理复杂任务的能力。a.) LLM大模型通过深度学习和自然语…

大模型平民化技术之LORA
1. 引言
在这篇博文中, 我将向大家介绍LoRA技术背后的核心原理以及相应的代码实现。
LoRA 是 Low-Rank Adaptation 或 Low-Rank Adaptors 的首字母缩写词,它提供了一种高效且轻量级的方法,用于微调预先训练好的的大语言模型。这包括 BERT 和…

【三维AIGC】扩散模型LDM辅助3D Gaussian重建三维场景
标题:《Sampling 3D Gaussian Scenes in Seconds with Latent Diffusion Models》 来源:Glasgow大学;爱丁堡大学 连接:https://arxiv.org/abs/2406.13099 提示:写完文章后,目录可以自动生成,如何…
llava1.5模型安装、预测、训练详细教程
引言
本博客介绍LLava1.5多模态大模型的安装教程、训练教程、预测教程,也会涉及到hugging face使用与wandb使用。
源码链接:点击这里
demo链接:点击这里
论文链接:点击这里
一、系统环境
ubuntu 20.04 gpu: 2*3090 cuda:11.6
二、LLava环境安装
1、代码下载…
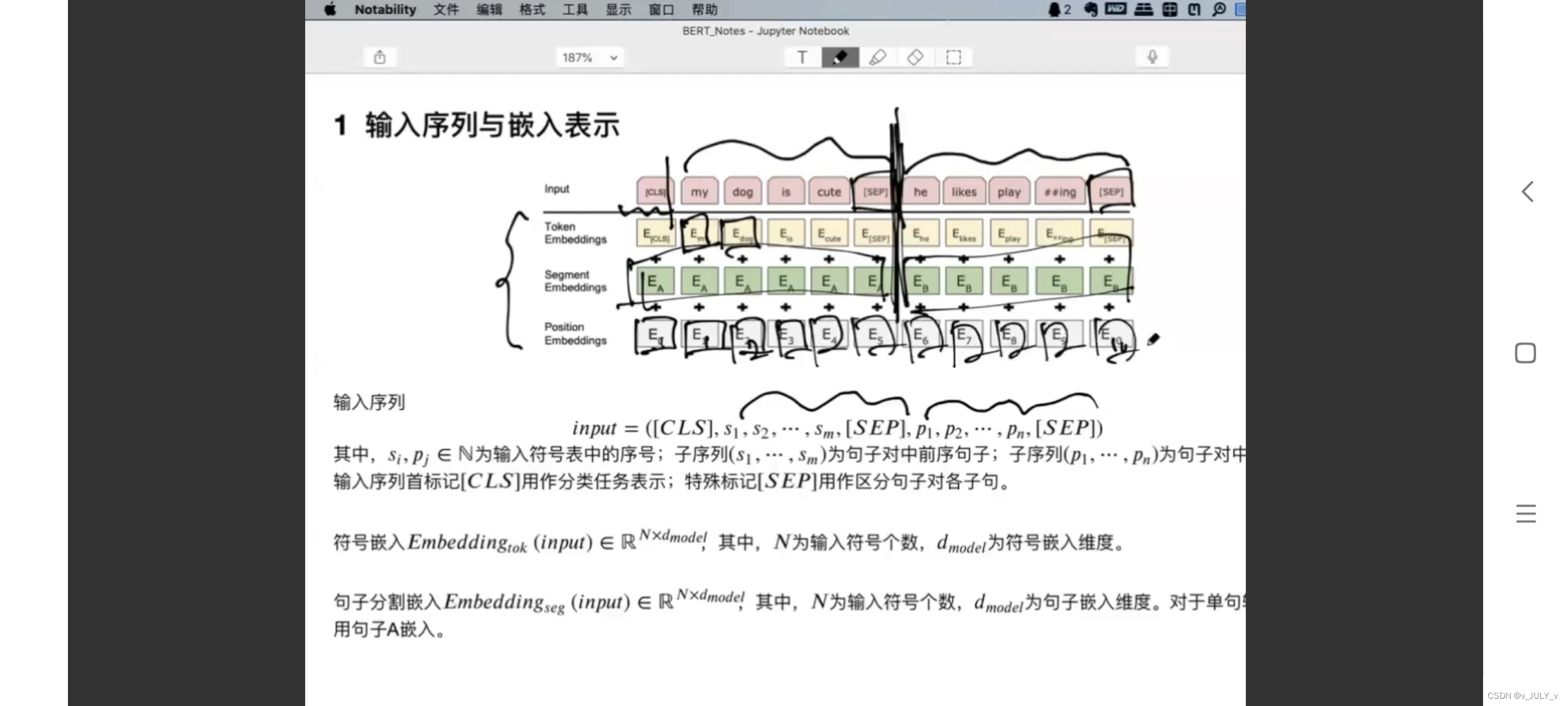
用通俗的方式讲解Transformer:从Word2Vec、Seq2Seq逐步理解到GPT、BERT
直到今天早上,刷到CSDN一篇讲BERT的文章,号称一文读懂,我读下来之后,假定我是初学者,读不懂。
关于BERT的笔记,其实一两年前就想写了,迟迟没动笔的原因是国内外已经有很多不错的资料࿰…

多模态大语言模型综述
节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学.
针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。
汇总合集&…

GPT-4 Turbo 发布 | 大模型训练的新时代:超算互联网的调度与调优
★OpenAI;ChatGPT;Sam Altman;Assistance API;GPT4 Turbo;DALL-E 3;多模态交互;算力调度;算力调优;大模型训练;GH200;snowflake;AGI;A…
AGI之MFM:《多模态基础模型:从专家到通用助手》翻译与解读之视觉理解、视觉生成
AGI之MFM:《Multimodal Foundation Models: From Specialists to General-Purpose Assistants多模态基础模型:从专家到通用助手》翻译与解读之视觉理解、视觉生成 目录
相关文章
AGI之MFM:《Multimodal Foundation Models: From Speciali…

COGVLM论文解读(COGVLM:VISUAL EXPERT FOR LARGE LANGUAGE MODELS)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、摘要二、引言三、模型方法1、模型思路2、融合公式 四、训练方法总结 前言
2023年5月18日清华&智谱AI发布并开源VisualGLM-6B以来,清华KEG&…

多模态大模型:解析未来智能汽车的新引擎
多模态大模型:解析未来智能汽车的新引擎 1. 多模态大模型简介2. 多模态大模型在智能汽车中的应用2.1 感知与认知2.2 智能驾驶辅助2.3 智能交互 随着人工智能技术的不断进步,智能汽车已经从概念变成了现实,成为了当今科技领域的焦点之一。而在…
AGI之MFM:《多模态基础模型:从专家到通用助手》翻译与解读之统一的视觉模型、加持LLMs的大型多模态模型
AGI之MFM:《Multimodal Foundation Models: From Specialists to General-Purpose Assistants多模态基础模型:从专家到通用助手》翻译与解读之统一的视觉模型、加持LLMs的大型多模态模型 目录
相关文章
AGI之MFM:《Multimodal Foundation…
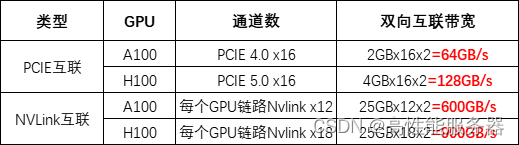
高性能计算与多模态处理的探索之旅:英伟达GH200性能优化与GPT-4V的算力加速未来
★多模态大模型;GPU算力;LLMS;LLM;LMM;GPT-4V;GH200;图像识别;目标定位;图像描述;视觉问答;视觉对话;英伟达;Nvidia&#…
领域大模型的挑战与机遇:从构建到应用
01
背景 来自 GPT4 的技术报告中指出,GPT4 仍处于通用人工智能(AGI)的初级阶段。而目前研发中的 GPT4.5 或 GPT5 则已展现出了 AGI 的某些特征。 GPT4 的出现给研究和工业界带来了巨大冲击,其显著特点是拥有强大的底座知识能力&a…

CIIS 2023丨聚焦文档图像处理前沿领域,合合信息AI助力图像处理与内容安全保障
近日,2023第十二届中国智能产业高峰论坛(CIIS 2023)在江西南昌顺利举行。大会由中国人工智能学会、江西省科学技术厅、南昌市人民政府主办,南昌市科学技术局、中国工程科技发展战略江西研究院承办。本次大会重点关注AI大模型、生成…
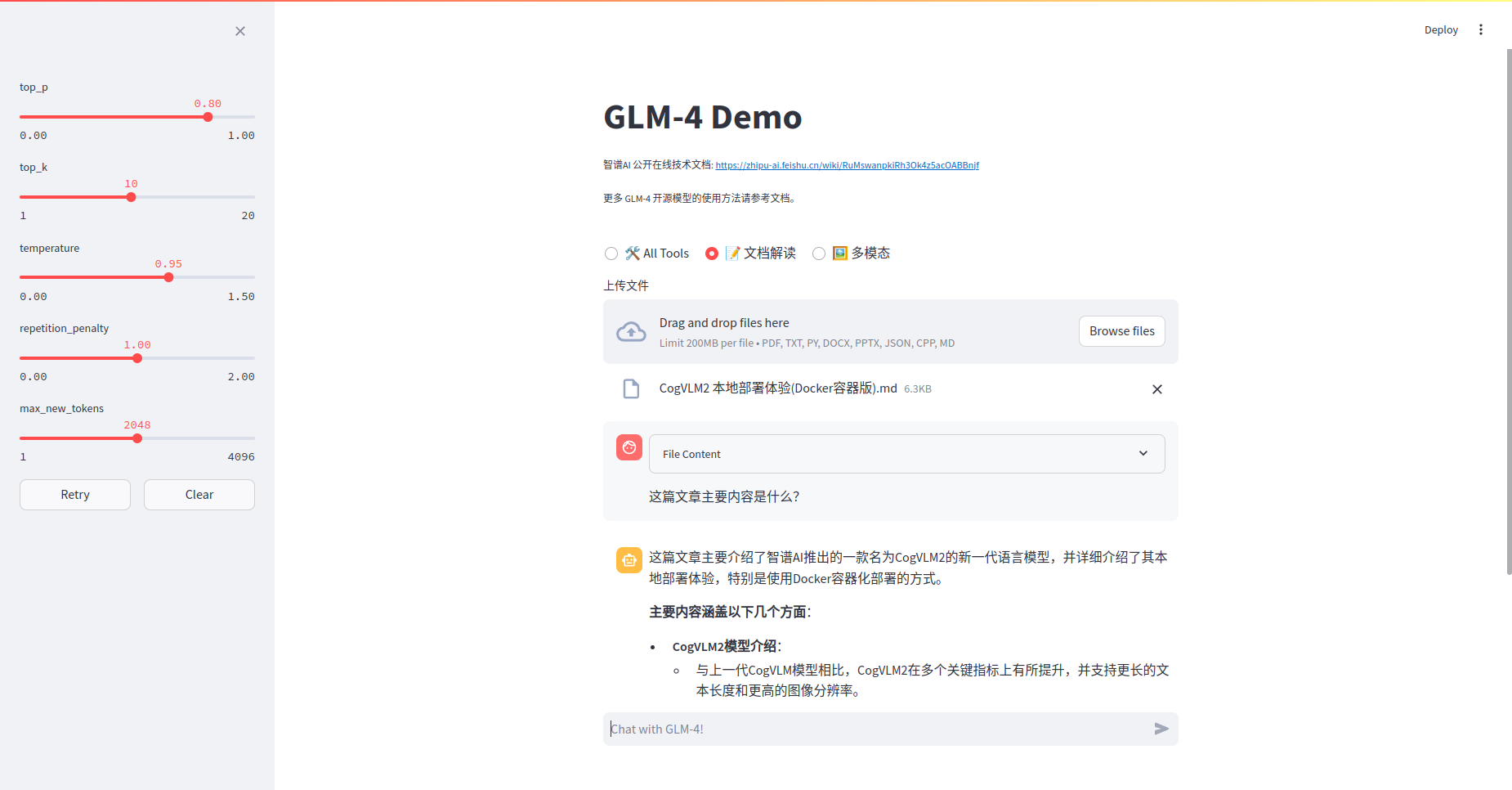
ChatGLM 4本地部署指南(Docker容器版)
GLM-4V-9B 是智谱 AI 推出的最新一代预训练模型 GLM-4 系列中的开源多模态版本。 GLM-4V-9B 具备 1120 * 1120 高分辨率下的中英双语多轮对话能力,在中英文综合能力、感知推理、文字识别、图表理解等多方面多模态评测中,GLM-4V-9B 都表现出卓越性能。 本…

清华和字节联合推出的视频理解大模型video-SALMONN(ICML 2024)
video-SALMONN: Speech-Enhanced Audio-Visual Large Language Models
论文信息
paper:https://arxiv.org/abs/2406.15704 code:https://github.com/bytedance/SALMONN/ AI也会「刷抖音」!清华领衔发布短视频全模态理解新模型 | ICML 2024 …

大模型背景下计算机视觉年终思考小结(一)
1. 引言
在过去的十年里,出现了许多涉及计算机视觉的项目,举例如下:
使用射线图像和其他医学图像领域的医学诊断应用使用卫星图像分析建筑物和土地利用率相关应用各种环境下的目标检测和跟踪,如交通流统计、自然环境垃圾检测估计…
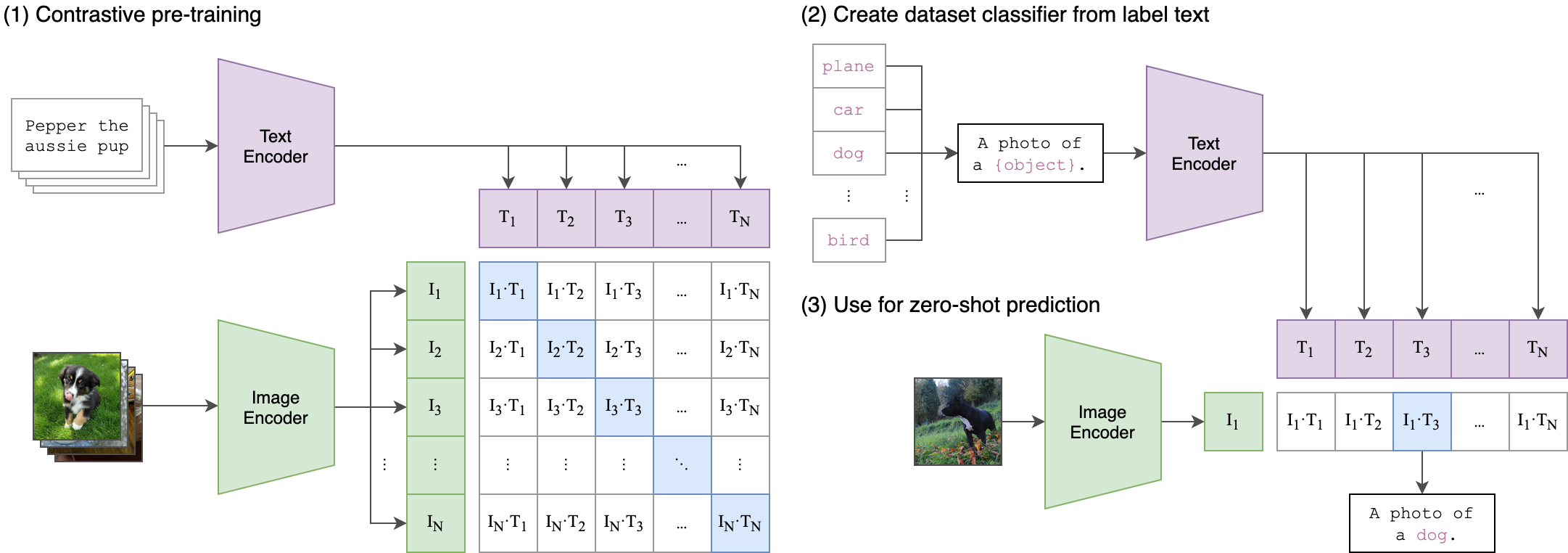
多模态对比语言图像预训练CLIP:打破语言与视觉的界限
项目设计集合(人工智能方向):助力新人快速实战掌握技能、自主完成项目设计升级,提升自身的硬实力(不仅限NLP、知识图谱、计算机视觉等领域):汇总有意义的项目设计集合,助力新人快速实…

Qwen2重磅发布!模型训练与推理实践来了!
暑期实习基本结束了,校招即将开启。
不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。提前准备才是完全之策。
最近,我们又陆续整理了很多大厂的面试题,…
多模态大模型:关于RLHF那些事儿
Overview 多模态大模型关于RLHF的代表性文章一、LLaVA-RLHF二、RLHF-V三、SILKIE多模态大模型关于RLHF的代表性文章
一、LLaVA-RLHF
题目: ALIGNING LARGE MULTIMODAL MODELS WITH FACTUALLY AUGMENTED RLHF 机构:UC伯克利 论文: https://arxiv.org/pdf/2309.14525.pdf 代码…

ConsiStory:Training-Free的主体一致性生成
Overview 一、总览二、PPT详解 ConsiStory 一、总览
题目: Training-Free Consistent Text-to-Image Generation 机构:NVIDIA, Tel-Aviv University 论文:https://arxiv.org/pdf/2402.03286.pdf 代码:https://consistory-paper.g…

PRCV 2023:语言模型与视觉生态如何协同?合合信息瞄准“多模态”技术
近期,2023年中国模式识别与计算机视觉大会(PRCV)在厦门成功举行。大会由中国计算机学会(CCF)、中国自动化学会(CAA)、中国图象图形学学会(CSIG)和中国人工智能学会&#…

大模型背景下计算机视觉年终思考小结(二)
1. 引言 尽管在过去的一年里大模型在计算机视觉领域取得了令人瞩目的快速发展,但是考虑到大模型的训练成本和对算力的依赖,更多切实的思考是如果在我们特定的小规模落地场景下的来辅助我们提升开发和落地效率。本文从相关数据集构造,预刷和生…
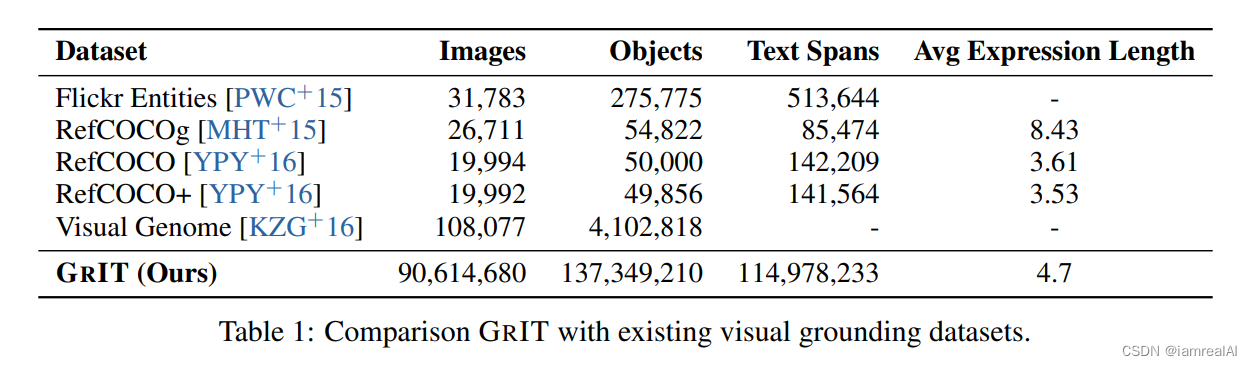
多模态大模型训练数据集汇总介绍
RefCOCO、RefCOCO、RefCOCOg 这三个是从MS-COCO中选取图像得到的数据集,数据集中对所有的 phrase 都有 bbox 的标注。
RefCOCO 共有19,994幅图像,包含142,209个引用表达式,包含50,000个对象实例。RefCOCO 共有19,992幅图像,包含1…

马赛克,克星,真来了!v2.0
大家好,今天继续聊聊 AI 开源项目
AI 开源项目
1、DemoFusion
AI 绘画的潜力还没有充分挖掘出来,仍然还有上升的空间。
DemoFusion 就是这么一个开源项目,继续深挖了 AI 绘画在高分辨率图片生成的效果。
提高分辨率,马赛克&a…